
Im ersten Teil der Blogreihe habe ich aufgezeigt, was man tun kann, wenn sich im Unternehmen über viele Jahre hinweg unzählige Daten angesammelt haben und aufgeräumt werden müssen. Das Programm OpenRefine ist eine große Hilfe, wenn es darum geht, diese Datenmengen zu bereinigen und zu optimieren. Die Lösung einer Problemstellung oder Aufgabe läuft in den folgenden fünf Schritten ab:
- Quelldaten einlesen
- Daten analysieren
- Daten aufräumen und optimieren
- Daten anreichern
- Daten im Zielformat ausgeben
Die Schritte eins und zwei habe ich im ersten Teil des Blogbeitrags erläutert. In diesem Teil erfahren Sie, was es mit den Schritten drei bis fünf auf sich hat.
3. Daten aufräumen und optimieren
Zur Optimierung der Daten steht eine große Anzahl Funktionen bereit, die typische Fehler bearbeiten und individuelle Lösungen für Problemstellungen ermöglichen:
- Leerzeichen am Anfang oder Ende der Werte entfernen.
- Mehrere aufeinanderfolgende Leerzeichen zusammenfassen.
- Konsequent alle Texte in Klein- oder Großbuchstaben umwandeln oder beginnend mit einem Großbuchstaben.
- Individuelle Zeichenketten ersetzen.
- Bestehende Daten über kleine Programme anpassen, die komplexe Regeln enthalten.
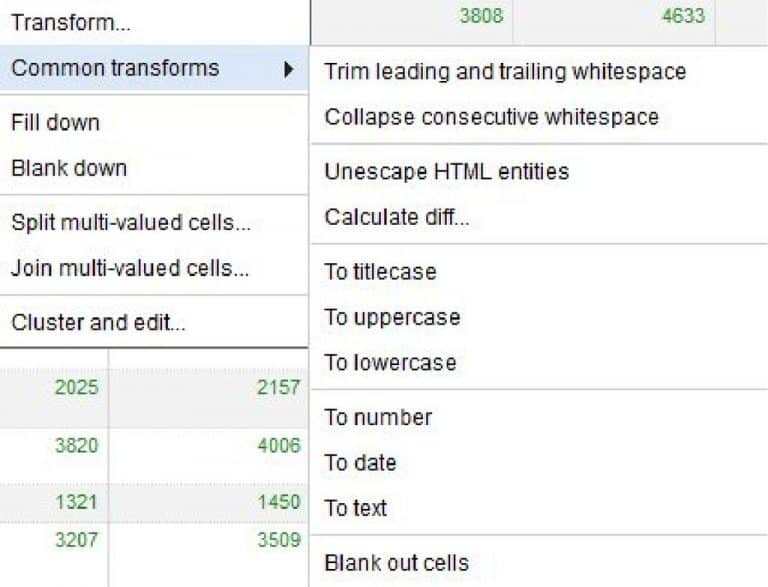
- Leere Werte mit dem jeweils übergeordneten oder untergeordneten Wert auffüllen, z. B. wenn Daten aus einer hierarchischen Quelle in Tabellen umgewandelt werden.
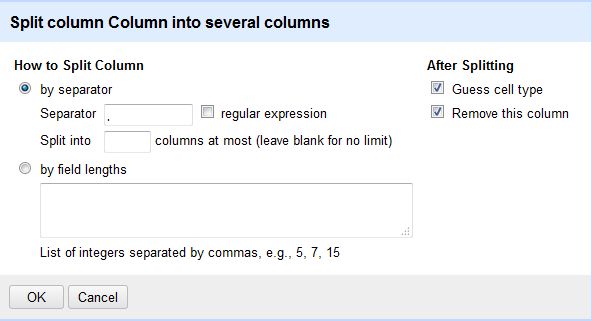
- Werte in Spalten auftrennen, basierend auf Trennzeichen, regulären Ausdrücken und Listen von Längenangaben.
- Gleiche Daten mit den erwähnten Fehlermerkmalen durch einen Standardtext ersetzen.
4. Daten anreichern
Die Ergänzung der Daten mit zusätzlichen Inhalten, die sich direkt oder unter Zuhilfenahme zusätzlicher Quellen ergeben, ist sicher eine der spannendsten Funktionen:
- Spalten ergänzen, basierend auf den Werten vorhandener Spalten und den festzulegenden Regeln.
Beispiele: Auftrennen von Sätzen in Wörter, Unterschiede von Werten in zwei Spalten, jede Art von regelbasierter Änderung von Texten, Umwandlung von spezifischen Entitäten aus Formaten wie HTML, XML, JSON, Berechnungen jeder Art. - Schlüssel erstellen, der ähnliche Sätze oder Begriffe als gleich kennzeichnet. Damit lassen sich beispielsweise Datensätze aus zwei verschiedenen Quellen basierend auf der Artikelbezeichnung gegenüberstellen.
- Werte aus HTML-Seiten herauslösen. Damit können Sie Informationen wie Artikeldaten automatisiert in Tabellen überführen.
Insgesamt stehen über 100 Funktionen zur Verfügung. Zusätzlich können externe Quellen mit den internen Daten verknüpft werden:
- Fakten-Datenbank „Freebase“ integrieren.
Beispiel: Wenn Werte einer Spalte z. B. eine Stadt definieren, lässt sich eine neue Spalte über „Freebase“ ergänzen, die die Einwohnerzahl enthält. - Zusätzliche Plug-Ins für die Integration weiterer Quellen.
- Für Anwender mit IT-Background: Alle Quellen von Webseiten bis zu Webservices ansprechen und auswerten.
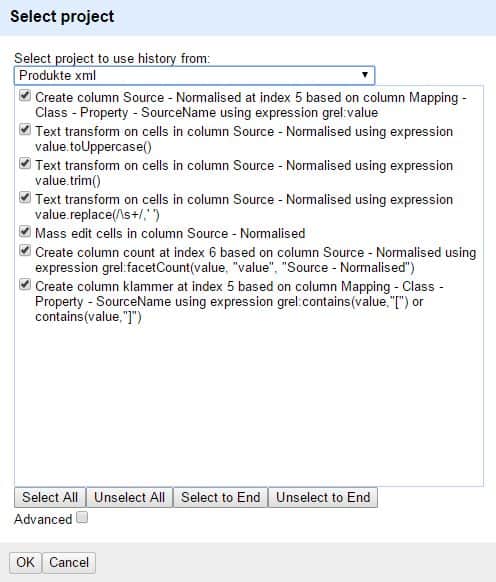
Alle Änderungen und Erweiterungen kann man jederzeit (während der Bearbeitung, aber auch nach Verlassen des Projekts und erneutem Öffnen) rückgängig machen oder wiederholen.
Das Bereinigen von Quelldaten ist und bleibt eine mühsame Detailarbeit. In vielen Fällen müssen gleiche oder ähnliche Abläufe immer wieder angewandt werden, da die Datenquellen nicht geändert werden können. Die Weiterverarbeitung muss jedoch immer auf sauberen Ständen basieren. Hierfür steht eine sehr einfache und mächtige Funktion zur Verfügung: Alle Aufgaben eines Projekts können dargestellt und komplett oder teilweise auf ein neues Projekt angewandt werden.
5. Daten im Zielformat ausgeben
Abschließend kann man die Daten wieder in verschiedene Formate exportieren (Excel, CSV, XML, JSON, eigene zu konfigurierenden Formate).
Im dritten Teil der Reihe stelle ich typische Problemstellungen vor und erkläre, wie man diese mit OpenRefine individuell löst.