Wenn es um digitale Transformation geht, rückt ein Thema für viele Industrieunternehmen besonders in den Fokus: der Umgang mit Produktinformationen, die in der aktuell vorliegenden Form digital nicht nutzbar sind. Datenblätter, technische Spezifikationen und Produktkataloge liegen oft als Printmedien oder in Formaten wie PDF, Excel oder Word vor – in medialen Formaten also, die in anderen digitalen Systemen und Plattformen schwer zu verarbeiten sind. Denn um Produktdaten effizient in allen Prozessen und Kanälen nutzen zu können, werden sie in digitaler und strukturierter Form benötigt.
Obwohl Industrieunternehmen in Sachen Digitalisierung laut verschiedener Studien einen Vorsprung vor anderen Branchen haben, gibt es auch hier viele Unternehmen, die die Digitalisierung bestehender Produktinformationen aus Zeit- und Kostengründen verschieben. Kein Wunder, in manchen Unternehmen liegen Hunderte oder gar Tausende technische Unterlagen, deren Informationsgehalt und damit Werte digital nicht genutzt werden können. Diese Bestandsdaten manuell – d. h. von Menschenhand – für die digitale Nutzung aufzubereiten, ist aufgrund der Datenmengen kaum möglich. Nun liegt der Gedanke nahe, die Aufbereitung mithilfe von intelligenten Technologien zu automatisieren und zu vereinfachen. Die zu digitalisierenden Ausgangsdokumente stellen Maschinen jedoch ebenfalls vor Herausforderungen.
Technische Unterlagen sind primär für menschliche Leser geschrieben, enthalten Ungenauigkeiten, Ungereimtheiten und sind nicht gleich aufgebaut. Menschen haben keine Probleme, mit solchen Informationen umzugehen, denn sie haben die dafür nötigen kognitiven Fähigkeiten, können abstrahieren und adaptieren. So intelligent Maschinen heute auch sind, diese heterogenen Bestandsdokumente sind maschinell oft schwer auswertbar.
Um diesem Problem zu begegnen haben wir bei TANNER über die letzten Jahre Instrumente und technische Verfahren entwickelt, mit deren Hilfe wir das Automatisierungspotenzial verschiedenster Datenformate maximieren können. Einen Prozess, mit dem Bestandsdaten digital nutzbar gemacht werden, möchte ich Ihnen in diesem Artikel vorstellen.
Toolbox für die Automatisierung
Egal für welches System Bestandsdaten aufbereitet werden sollen, in jedem Fall müssen die relevanten Informationen aus den vorliegenden Dokumenten extrahiert werden. Für diese Aufgabenstellung haben wir bei TANNER eine Toolbox entwickelt. Mit dieser können wir beliebige Quellformate in eine NoSQL-Datenbank einlesen, schnell und einfach technische Regeln anwenden und die relevanten Informationen in das gewünschte Zielformat umwandeln.
Ich möchte das am Beispiel von PDF-Dokumenten mit technischen Spezifikationen beschreiben. Die automatisierte Aufbereitung dieser Daten kann problematisch sein, weil PDFs einerseits Endformate sind, die digital nicht strukturiert verarbeitet werden können, andererseits weil der Aufbau solcher Dokumente oft nicht homogen ist.
Um aus diesen PDFs technische Merkmale für die Verwendung in einem PIM-System zu extrahieren, konvertieren wir die Dateien zunächst nach XML. In diesem Format sind die Informationen zwar verarbeitbar, aber noch nicht weiter strukturiert. Daher werden im nächsten Schritt technische Regeln definiert, um die relevanten Informationen in ein strukturiertes XML zu überführen, welches in andere Systeme und Tools importiert werden kann.
Wie könnte eine technische Regel aussehen?
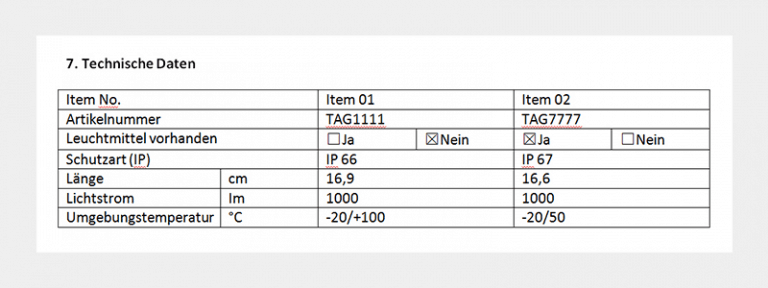
Ausschnitt aus einer technischen Spezifikation
Im Bild sehen Sie die Daten von zwei Produkten in einer technischen Spezifikation. Angenommen, es soll nun das Produktmerkmal „Leuchtmittel vorhanden“ extrahiert werden, dann könnte man die technischen Regeln dafür wie folgt in Worte fassen:
- „Suche eine H1-Überschrift, die ‚Technische Daten‘ enthält.“ (Weil nach solchen Überschriften im Beispiel-Dokument immer eine Tabelle folgt.)
- „Suche nun eine direkt nachfolgende Tabelle.“
- „Suche in der Tabelle die Zelle, die ‚Leuchtmittel vorhanden‘ enthält.“ (Weil der Wert rechts daneben im Beispiel immer der relevante Inhalt ist.)
- „Extrahiere den Wert in der Zelle rechts von ‚Leuchtmittel vorhanden‘ nur, wenn die Checkbox links des Wertes gecheckt ist.“ (Um nur gültige Inhalte zu extrahieren .)
Vereinfachtes Datenmodell für effiziente Datennutzung
Auf die beschriebene Weise lassen sich relevante Informationen schnell und zum großen Teil automatisiert aus Bestandsdaten extrahieren. Für die weitere Nutzung dieser Daten in verschiedenen Kanälen empfiehlt sich zum Beispiel der Import in ein PIM-System. Wie stark differenziert Produktdaten dafür vorliegen müssen, hängt von den individuellen Anwendungszwecken ab.
Ein vollumfängliches Datenmodell mit 50 oder mehr Produktmerkmalen wäre natürlich ein eher zeit- und kostenintensiveres Projekt. Oft ist es allerdings gar nicht nötig, ältere Produktdaten derart differenziert aufzubereiten. Bei TANNER haben wir daher in der Praxis erprobte Konzepte für vereinfachte Datenmodelle entwickelt. Darin werden besonders relevante Produktmerkmale differenziert aufbereitet, während weitere Merkmale mithilfe von Freitextfeldern nutzbar sind. Vor allem wenn Quelldokumente unterschiedlich strukturiert sind, ermöglicht dies eine höhere Flexibilität bei der Datenerfassung als spezifische Felder. Trotzdem sind die Daten nun so granular, dass spezifische Informationen schnell gefunden und miteinander verglichen werden können.
Fazit
Dank der automatisierten Aufbereitung von Bestandsdaten mithilfe von technischen Regeln sowie der Verwendung eines vereinfachten Datenmodells im PIM-System sind wir beispielsweise in der Lage, auch große Datenmengen innerhalb kurzer Zeit aufzubereiten. Für die manuelle Datenaufbereitung wäre der 10-fache Aufwand notwendig.